Benchmarks¶
Setup¶
There are a number Python modules providing APIs for histogram calculations. Here we see how pygram11 performs in comparison to numpy, fast-histogram, and boost-histogram. Tests were performed on an Intel i7-8850H 2.60Gz processor (6 physical cores, 12 threads).
Fast-histogram does not provide calculations for variable width bins, so, when benchmarking variable width bins, we only compare to NumPy and boost-histogram.
Results¶
The results clearly show that pygram11 is most useful for input arrays exceeding about 5,000 elements. This makes sense because the pygram11 backend has a clear and simple overhead: to take advantage of N available threads we make N result arrays, fill them individually (splitting the loop over the input data N times), and finally combine the results (one per thread) into a final single result that is returned.
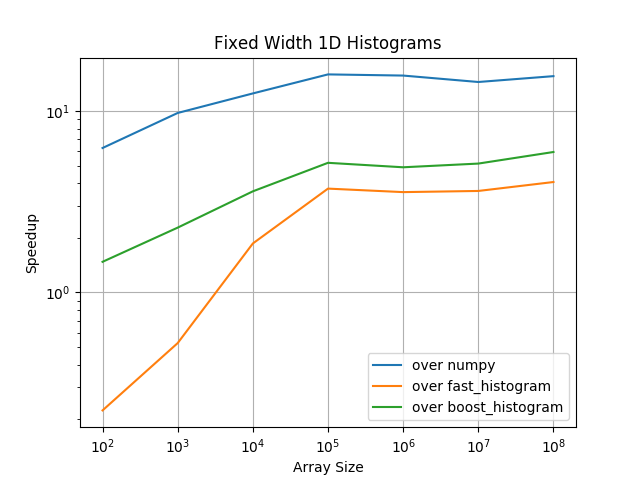
For one dimensional histograms with fixed width bins pygram11 becomes the most performant calculation for arrays with about 5,000 or more elements (up to about 3x faster than the next best option and over 10x faster than NumPy). Fast-histogram is a bit more performant for smaller arrays, while pygram11 is always faster than NumPy and boost-histogram.
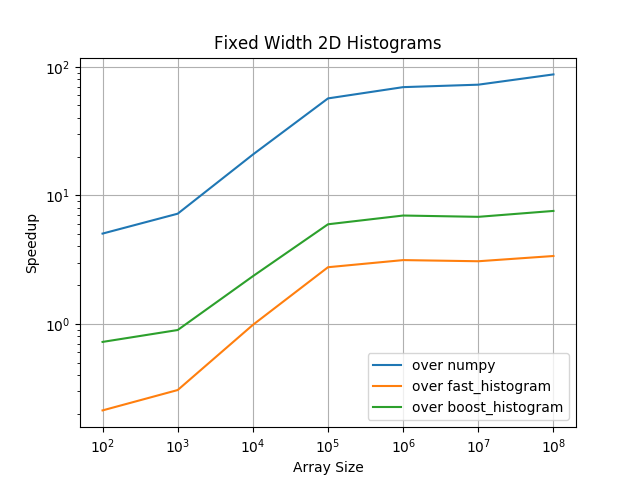
For two dimensional histograms with fixed width bins pygram11 becomes the most performant calculation for arrays with about 10,000 or more elements (up to about 3x faster than the next best option and almost 100x faster than NumPy). Fast-histogram is again faster for smaller inputs, while pygram11 is always faster than NumPy and almost always faster than boost-histogram.
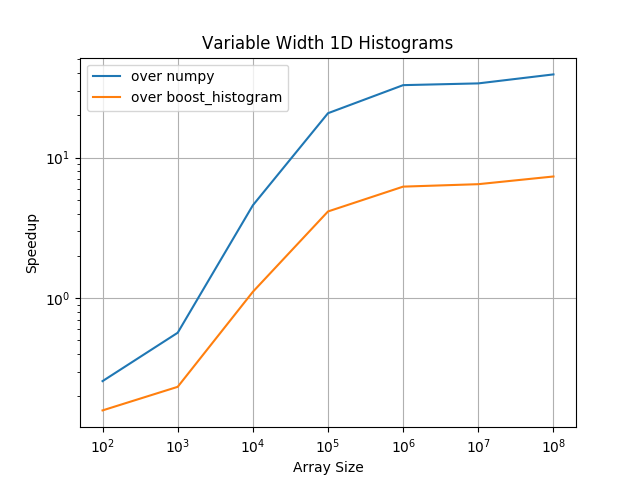
For one dimensional histograms with variable width bins pygram11 becomes the most performant option for arrays with about 10,000 or more elements (up to about 8x faster than the next best option and about 13x faster than NumPy).
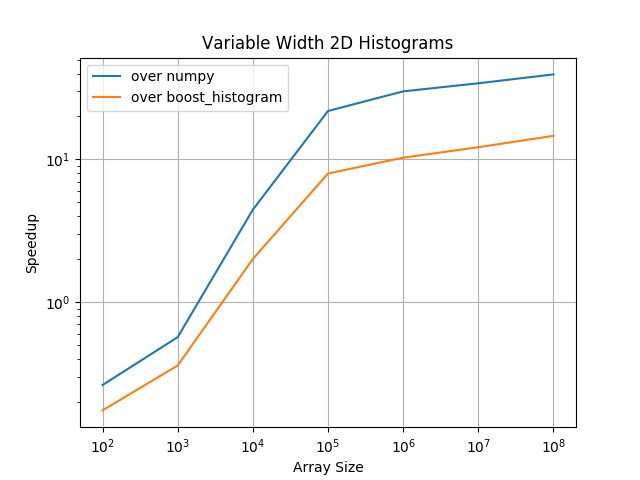
For two dimensional histograms with variable width bins pygram11 becomes the most performant option for arrays with about 5,000 or more elements (up to 10x faster than the next best option).